Как производится расшифровка штрих-кода товара для различных стандартов кодирования

Штрих-код — это совсем не секретные данные. Даже видя перед собой только «полоски», любой человек может преобразовать их в понятную для себя информацию, задействовав тот или иной общедоступный инструмент для расшифровки кода. Рассмотрим, как выполняется расшифровка штрих-кода товара, что данная процедура собой представляет и с помощью чего она может быть осуществлена.
Что понимать под «расшифровкой» (и «шифровкой») штрих-кода
Штрих-код — это последовательность темных и светлых элементов (традиционно — полосок и пробелов, но современные коды намного сложнее) различной ширины, размещенных на идентифицируемой поверхности (упаковке товара, бумажном листке, коробке, экране) в соответствии с определенным стандартом. Каждому (большинству) из этих элементов по отдельности или в совокупности с другими (одним или несколькими) соответствует тот или иной тип данных, приспособленных к прочтению человеком. То есть:
- букв, цифр (одной или нескольких);
- точек, запятых и иных символов (используемых, так или иначе, при клавиатурном вводе данных и отображении информации на дисплее компьютера).
Таким образом, под «расшифровкой» штрих-кода следует понимать обнаружение соответствия между темными и светлыми элементами кода — отдельными или представленными в сочетаниях друг с другом, и между понятными для человека данными — которые привязаны к соответствующим элементам по принятому стандарту кодирования.
Примеры соответствий между сочетаниями полосок (и пробелов) и «понятными для человека данными» по стандарту Code 39:

«Понятные для человека данные», таким образом, чаще всего бывают представлены текстом или числами. В зависимости от их содержания, они могут требовать или не требовать дополнительной интерпретации. В случае применения традиционных одномерных штрих-кодов — чаще всего, конечно, требуют. Прежде всего — потому, что простой набор букв и цифр, становящийся результатом «расшифровки», человеку, как правило, ничего не говорит. Их надо интерпретировать.
В целях такой интерпретации могут использоваться самые разные инструменты. Как правило — различные базы данных (регламентированные теми же стандартами), в которых заложены соответствия между:
- буквами и цифрами — результатами «расшифровки»;
- реально полезными для человека данными.
В свою очередь, «реально полезные данные» (например, характеристики товара — представленные страной его происхождения, наименованием, весом, сроком годности) в дальнейшем представляются человеку в установленном порядке. Элементарно — в виде отформатированного текста, который можно читать.
Применение баз с «соответствиями» обусловлено тем фактом, что в самом одномерном коде невозможно зашифровать большой объем данных. Как правило, емкость кода ограничивается несколькими десятками букв или цифр. В свою очередь, каждой букве или цифре (сочетанию букв и цифр) может найтись какое угодно «длинное» соответствие в базе.
Таким образом, «расшифровка» штрих-кода — это трехступенчатая процедура, при которой:
- Штрих-код переводится в «понятные для человека данные».
Чаще всего — буквы или цифры.
- «Понятным для человека» данным находится соответствие в виде «реально полезных данных» по базе, что предусмотрена стандартом.
- «Реально полезные данные» в установленном порядке представляются человеку.
В свою очередь, «шифровка» — это, очевидно, поиск обратного соответствия, когда исходным «понятным для человека» данным (что имеют, в свою очередь, соответствие в базе «реально полезных» данных) находится соответствие в виде «полосок и пробелов» по тому или иному стандарту.
Рассмотрим теперь то, какие основные принципы лежат в основе функционирования штрих-кода — каким образом осуществляется шифрование на практике.
Основные принципы шифрования данных на примере одномерного штрих-кода
Штрихи и пробелы в одномерном штрих-коде, как правило, имеют разную ширину, но одинаковую длину (условимся вести речь о простейшем линейном коде — который повсеместно распространен на товарах, что продаются в магазинах). Ширина самого узкого штриха либо пробела в рамках используемого стандарта принимается за условную единицу — модуль. Любые другие элементы в штрих-коде должны:
- иметь ширину, что кратна модулю;
- быть равными по ширине модулю или быть шире него в пределах разрешенной пропорции.
По одному стандарту полоске или пробелу (шириной в заданное количество модулей — или увеличенной в заданной пропорции относительно модуля) может соответствовать одна буква, по другому аналогичной полоске или пробелу — совсем другая. В свою очередь, одна и та же буква может быть «зашифрована» по разным стандартам штрих-кодирования и иметь соответствие в виде разных полосок и пробелов (сочетаний полосок и пробелов) исходя из используемого стандарта.
От стандарта также зависят:
- Порядок определения целостности штрих-кода (установления факта корректного отображения в нем всех предусмотренных стандартом пробелов и полосок).
Можно отметить, что полный штрих-код в терминологии специалистов в области штрих-кодирования называется символом. При этом, как правило, самая первая полоска в символе (крайняя слева) и последняя (крайняя справа) обозначают его границы: в них не шифруются «полезные» данные. Но стандарт может предусматривать и иные принципы установления границ кода.
- Наличие или отсутствие в составе кода различных дополняющих его элементов.
Например — дополнительных цветных линий (которые в сочетании с определенными полосками или пробелами могут тем или иным образом видоизменять ту «шифровку», что соответствует данным полоскам или пробелам по умолчанию — если цветной линии нет). Или же различные контрольные элементы — позволяющие при необходимости установить правильность структуры штрих-кода.
Теоретически и шифровка и расшифровка штрих-кода могут быть произведены человеком. Он может внимательно изучить описания к используемому стандарту штрих-кодирования, вооружиться линейкой — и, измеряя штрих-код (его модули) «по полоске» (находя соответствие «полосок» и букв), найти соответствия, о которых мы сказали выше. Но, понятное дело, на практике это занятие бесперспективное: эти соответствия ищет машина, гораздо более производительная в части вычислений в сравнении с человеком.
Считав штрих-код — с использованием сканера, компьютер «расшифровывает» его, а получившиеся данные обрабатывает в установленном порядке (или — передает на дальнейшую обработку человеку — поскольку они уже будут в понятном для него виде).
Рассмотрим подробнее — что именно может шифроваться в кодах, формируемых по современным распространенным стандартам, и каковы особенности расшифровки таких штрих-кодов на практике.
Что «шифруется» в одномерных (линейных) кодах
Исторически самый первый тип штрих-кода — одномерный (или линейный). Это традиционный штрих-код, состоящий из вертикальных полосок и пробелов одинаковой (в большинстве случаев) длины. В нем могут быть зашифрованы самые разные данные — как текстовые, так и числовые.
Можно выделить следующие общераспространенные стандарты штрих-кодирования:
- EAN 13 и EAN 8.
Эти коды — именно те, что размещены на большинстве товаров, продаваемых в российских магазинах. По ним можно узнать, в какой стране произведен товар (точнее, для какой страны — но первое определение часто находит буквальное соответствие), каким заводом (официально), и наименование товара (официально). В принципе, все те же сведения указываются на упаковке и текстом. Но в коде — более «концентрированно» (и, к тому же, по стандарту, который облегчает учет движения товара — собственно, для его целей код в первую очередь и используется).
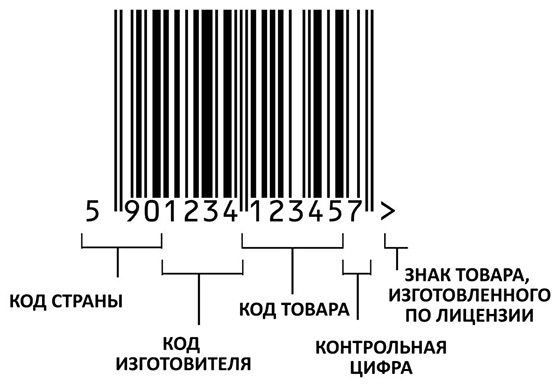
Рассматриваемые штрих-коды содержат числовые данные. Если говорить о коде EAN-13, то в нем предусматривается шифрование 13 цифр (из них 1 — контрольная, и не «соотносится» с «понятной» информацией):
- первые 2-3 обозначают страну происхождения товара;
- следующие 4 или 5 (соответственно, если применено 3 или 2 цифры для страны происхождения товара) идентифицируют завод-производитель;
- следующие 5 — идентифицируют сам товар (товарную позицию).
Последняя цифра кода — контрольная.
EAN-8 – укороченная версия кода EAN-13. В нем шифруются только:
- страна-производитель;
- код завода;
- контрольное число.
Примечательно, что в рамках стандарта EAN-13 возможно шифрование не только указанного перечня данных, но и любых других, которые можно распределить по составляющим кода подобно тому, как распределены эти данные. Так, общераспространено использование стандарта для штрих-кодирования весовых товаров (при прикреплении стикеров со штрих-кодом после взвешивания на электронных весах). В этом случае в состав кода будут входить:
- префикс (2 первые цифры);
- кода товара (5 следующие цифр);
- вес товара в граммах (следующие 5 цифр);
- контрольная цифра.
На основе кода EAN-13 также формируются различные отраслевые коды. В их числе — ISBN (идентификатор книги), ISSN (идентификатор периодического печатного издания).
- Чередующиеся 2 и 5 (ITF).
Распространено английское наименование кода — Inteleaved 2 of 5. Его особенность — в приспособленности к шифрованию информации любой длины — но только числовой, и при условии, что количество цифр будет четным. Кодирование осуществляется в соответствии с параметрами ширины штрихов и пробелов с применением 2 полос с 5 разными ширинами.
Код распространен, главным образом, в складских организациях (например, в целях идентификации ящиков с товарами). Во многих случаях код реализован в стандарте ITF-14. Он считается одним из наиболее приспособленных для нанесения на гофрированные поверхности.
- GS1-128.
Считается одним из главных международных идентификаторов грузов. В коде может быть зашифрована самая разная информация — например:
- срок годности товара;
- размеры товара, объем;
- код самого товара или партии.

Кодироваться могут любые «понятные» данные — как текстовые, так и числовые (с использованием словаря по другому популярному стандарту — Code 128). В свою очередь, «реально полезные» данные по коду заложены в базах GS1. Именуются они «идентификаторами применения» — которых несколько десятков ().
- Code 39.
Весьма универсальный код: с одной стороны, довольно емкий (позволяет кодировать большие латинские буквы, цифры и некоторые дополнительные символы), с другой — не слишком большой по размеру. Это позволяет его использовать в разных сферах хозяйства — в промышленности, в транспорте, военной индустрии.

- Codabar.
Данный код рассчитан на шифрование куда более скромного перечня данных — цифр от 0 до 9, букв A, B, C, D и некоторые символы. Относится к не самым популярным кодам (и может использоваться, к примеру, в библиотечном деле). Однако остается востребованным благодаря легкости сканирования и наличию элементов самоконтроля — для автоматической проверки на ошибки.
Теперь — о двумерных штрих-кодах, ставших результатом совершенствования технологии штрих-кодирования. Первые образцы таких кодов появились в начале 90-х годов — сильно позже одномерных штрих-кодов. Общераспространенными двумерные идентификаторы стали относительно недавно — благодаря повсеместному распространению общедоступных средств их распознавания, которых раньше в промышленных масштабах не было (и в быту их применять было затруднительно).
Что «шифруется» в двумерных кодах
Двумерный штрих-код — действительно более технологически продвинутый в сравнении с линейным. В нем присутствуют не полоски и пробелы (не только они), а иные, более сложные по формам элементы — квадраты, точки, линии и иные. Вариантов их взаимного расположения — несопоставимо больше в сравнении с вариантами взаимного расположения «пробелов и полосок», и потому в один двумерный штрих-код можно зашифровать намного больший объем данных в сравнении с одномерным кодом.
Как и в случае с традиционными кодами, порядок взаимного расположения «квадратов, точек и линий» — и порядок установления соответствия им (их сочетаниям) «понятных для человека» данных (как и «реально понятных данных») определяется по конкретному стандарту штрихового кодирования.
Отличительная особенность двумерных штрих-кодов в том, что в них изначально зашифрованы преимущественно «реально полезные данные» — то есть, готовая к восприятию информация. Во многих случаях нет промежуточной стадии, при которых «полезные данные» — полученные сразу из кода, сопоставляются с информацией по базе, что предусмотрена стандартом. Но поиск такого соответствия, безусловно, может производиться на регулярной основе.
«Одноступенчатая» расшифровка двумерного штрих-кода возможна как раз благодаря его большой емкости: нет необходимости, в отличие от линейного кода, размещать часть данных на стороннем источнике. При этом, для соответствующей расшифровки, как правило, требуется значительная вычислительная мощность. Раньше она обеспечивалась встраиванием в сканеры штрих-кодов дорогостоящих высокопроизводительных микросхем. Сейчас — аналогичную производительность показывают даже самые дешевые мобильные гаджеты. Также подешевели и сами сканеры — оснащенные необходимыми аппаратными компонентами. Собственно, этим и обусловлен тот факт, что двумерные штрих-коды — относительно новое явление для массового рынка.
Можно выделить следующие популярные стандарты двумерного штрих-кодирования:
- QR-код.
Легко узнается по наличию 3-х квадратов, расположенных на правом верхнем, правом и левом нижних углах. Изначально был создан для автомобильных производителей из Японии. Но впоследствии стал применяться повсеместно — в том числе и в розничной торговле. Может шифровать практически любые данные — текстовые, числовые. Теоретически — даже простейшие исполняемые команды и графические изображения небольшого объема.

На практике код применяется в целях отслеживания движения товаров, идентификации отдельных объектов, времени их обработки, обеспечения коммуникации между поставщиком и потребителем. Популярно использование QR-кода в качестве визитной карточки в бизнесе.
QR-код вмещает данные объемом до нескольких килобайт. Оптимально размещение 2-3 КБ — так, чтобы функционировали алгоритмы защиты информации от ошибок прочтения, которые предусмотрены стандартом (при их использовании можно обеспечить прочтение кода, если на нем повреждено до 30% информации). Благодаря данной опции QR-коды можно различным образом модифицировать — например, добавляя на некоторые его участки рисунки (как вариант, фирменные логотипы). Это позволит выделить код среди остальных, и при этом сохранить возможность считывания информации с него (разумеется, если остальные участки вне рисунка не будут повреждены).
При необходимости можно использовать особую разновидность идентификатора — Micro QR. Он позволяет зашифровать до 35 цифр и до 21 буквы на участке минимальной площади. Во многих случаях — существенно меньшей в сравнении с той, что занимал бы одномерный штрих-код, в котором зашифрованы аналогичные данные.
- DataMatrix.
Этот код примечателен тем, что именно его российский законодатель выбрал в качестве идентификатора для системы маркировки (к 2024 году, как ожидается, в рамках нее будут маркироваться большинство современных потребительских товаров).

По основным характеристикам стандарт очень схож с QR, и по внешнему виду коды похожи. Код DataMatrix имеет почти тот же уровень защищенности — когда данные считываются при повреждении до 30% поверхности кода.
DataMatrix узнаваем по двум перпендикулярным линиям по правому и нижнему краям. Одно из преимуществ кода — в возможности формировать его не только в квадратном, но и в прямоугольном виде.
- Aztec.
Данный двумерный код узнаваем по «глазу» в самом центре — в виде нескольких заключенных друг в друга квадратов. По своему назначению и характеристикам также очень схож с QR и DataMatrix, но имеет уникальное преимущество — в виде приспособленности к считыванию при повреждении в некоторых случаях до 90% поверхности. Правда, на этот показатель следует ориентироваться, только если объем записываемых данных не слишком большой. Если он составляет те же 2-3 КБ, то исправление ошибок, как правило, возможно, если код поврежден не более, чем на те же 30%.

Код отлично приспособлен к считыванию под большим углом: сканер ориентируется на «глаз» и на другие корректирующие элементы.
Еще одна особенность кода — в возможности размещать его на объекте, не обеспечивая пустого пространства между краями кода и другими графическими объектами. Условно говоря, код можно разместить на самом краю идентифицируемого объекта.
Теперь — ознакомимся с практическим инструментарием для расшифровки (и «шифровки») одномерных и двумерных штрих-кодов.
Какие инструменты существуют для расшифровки штрих-кода товара (и «шифровки»)
Алгоритмы для расшифровки одномерных и двумерных штрих-кодов, как правило, по умолчанию заложены в большинство современных средств их распознавания — то есть, сканеров, используемых в той или иной отрасли. Прежде всего — кассовых, складских, промышленных сканеров.
Общедоступны различные мобильные приложения для расшифровки штрих-кодов — например, Barcode Scanner ().
QR сканер штрих-кода ().
Во многих случаях мобильные приложения могут, таким образом, осуществлять не только расшифровку кода с точки зрения вычисления «понятных» данных — но и представлять пользователю «реально понятные» данные.
Есть много сайтов, где можно расшифровать тот или иной код — загрузив его изображение в виде графического файла (например, этот сайт — ).
Правда, функционал таких сайтов во многих случаях ограничен приведением только «понятных» данных. Но пользователь по желанию сам может найти «реально понятные».
Например, если в его распоряжении — код EAN-13 по товару, произведенному в России, то он может, введя данный код на специальной странице сайта российского представительства GS1, загрузить по нему ключевые сведения о товаре — .
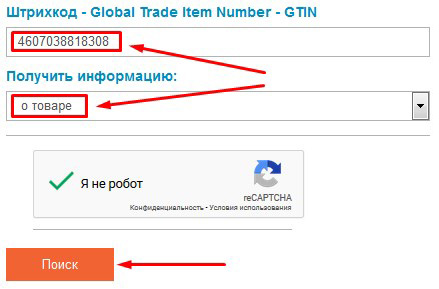

В свою очередь, «шифровка» кода может быть произведена разными способами — в зависимости от конкретного стандарта и назначения кода. Если требуется сформировать уникальный (и легальный) товарный код EAN-13, то нужно обращаться в GS1: данная организация присвоит определенные стандартом идентификаторы производителя и товара.
Если нужно сформировать QR-код на основании текстовых данных, то можно задействовать какой-либо из общедоступных онлайн-сервисов (например, ).
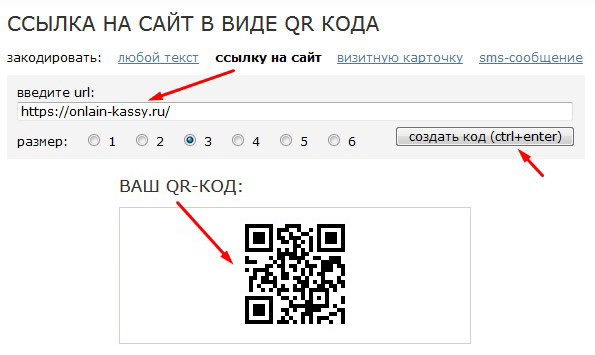
Есть много сервисов и для одномерных кодов со свободным подбором шифруемых данных (например, ).

Их можно использовать, если, как вариант, необходимо зашифровать весовой код с помощью стандарта EAN-13, или присвоить код грузу по стандарту GS1-128.
Резюме
Штрих-кодирование — повсеместная процедура. Ее можно производить, используя традиционные одномерные коды или инновационные двумерные. В этих целях есть варианты задействовать большое количество общедоступных онлайн-инструментов. Опции для расшифровки кодов заложены во многие современные вычислительные устройства — как узкоспециализированные (кассовые и промышленные сканеры штрих-кодов), так и устройства общего назначения (мобильные гаджеты, компьютеры).
 Где и как можно бесплатно найти товар по штрих-коду онлайн и что для этого потребуется.
Где и как можно бесплатно найти товар по штрих-коду онлайн и что для этого потребуется.
Обзор некоторых онлайн-серисов, позволяющих удаленно создавать свои собственные ценники и распечатывать их.
Особенности применения 2D-сканера https://onlain-kassy.ru/markirovka/2d-skaner-dlya-sigaret.html при расшифровке штрих-кода на пачках сигарет.
Для успешного ведения бизнеса можно подобрать необходимое оборудование для , , , и других направлений предпринимательской деятельности.